分布式数据库系统在软件开发中的核心特点与优势

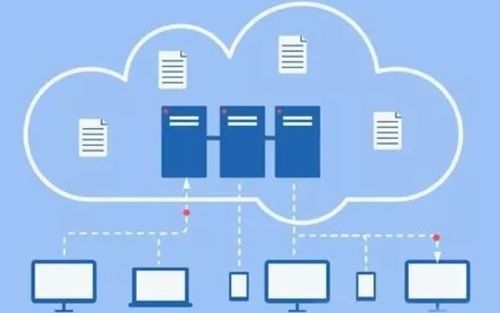
分布式数据库系统(Distributed Database System,简称DDBS)是随着现代应用对数据处理能力、可用性和扩展性要求不断提升而发展起来的关键技术。在软件开发领域,理解其核心特点对于设计高并发、高可用的现代应用架构至关重要。
1. 数据分布性与透明性
数据分布性是分布式数据库最根本的特征。数据并非集中存储在单一服务器上,而是物理地分布在不同地理位置或网络节点的多个数据库上。这种分布可以是水平的(按行分片)、垂直的(按列分片)或混合式的。
与之相辅相成的是透明性,这是对软件开发者的巨大福音。系统通过中间件或自身架构,向应用层隐藏了数据分布的复杂性,主要体现为:
- 位置透明性:开发者编写SQL查询时,无需知道数据具体存储在哪个节点。
- 分片透明性(或分片透明性):无需关心数据是如何被分片或复制的。
- 复制透明性:系统自动管理数据的多个副本,应用感知不到副本的存在。
这种透明性极大地降低了软件开发的复杂度,使开发者可以像操作单一数据库一样进行编程。
2. 高可用性与可靠性
这是分布式数据库在软件架构中备受青睐的核心原因。通过数据冗余复制(如主从复制、多主复制、Paxos/Raft协议下的多副本),当一个或多个节点发生故障时,系统能自动将请求路由到健康的副本上,保证服务持续可用。对于需要7x24小时不间断运行的电商、金融、社交等软件而言,这一特点是业务连续性的根本保障。
3. 可扩展性(Scalability)
面对用户量和数据量的快速增长,传统的集中式数据库在纵向扩展(Scale-up)上会遇到硬件瓶颈和成本急剧上升的问题。分布式数据库则擅长横向扩展(Scale-out)。软件开发团队可以通过简单地增加廉价的商用服务器节点来线性地提升系统的整体存储容量和处理能力(吞吐量)。这种弹性扩展能力完美契合了互联网应用快速迭代和增长的需求。
4. 提升性能与本地自治
分布式数据库可以将数据和计算就近部署到用户所在的区域。例如,将亚洲用户的数据主要存储在亚洲的节点上,可以显著降低查询延迟,提升用户体验。每个本地节点可以独立管理自身的数据,处理本地的大部分事务,具备一定的本地自治性,这减少了对中心节点的依赖和网络传输开销,从而从整体上提升了系统性能。
5. 并发事务处理与一致性挑战
在分布式环境下,多个节点同时处理事务带来了新的挑战。分布式数据库需要实现分布式事务管理,通常采用如两阶段提交(2PC)等协议来保证跨节点事务的原子性。根据CAP定理,在网络分区(P)存在的情况下,系统需要在一致性(C)和可用性(A)之间做出权衡。因此,不同的分布式数据库提供了不同的一致性级别供软件开发中选择:
- 强一致性:如分布式关系型数据库,保证所有节点看到的数据在同一时刻完全相同,但可能影响可用性。
- 最终一致性:如许多NoSQL数据库,允许短时间内数据副本间存在不一致,但最终会达到一致状态,以此换取更高的可用性和分区容错性。
对软件开发的影响与考量
对于软件开发者而言,采用分布式数据库意味着:
- 架构设计先行:需要在设计初期就考虑数据的分片策略(如按用户ID哈希、按地域范围)。
- 权衡选择:根据业务场景(如银行交易 vs. 社交动态)在一致性、可用性、延迟之间做出合适的选择。
- 复杂性转移:虽然应用层编程得到简化,但运维的复杂性有所增加,需要关注节点监控、数据均衡、分布式事务回滚等问题。
- 新工具与范式:需要学习和适应新的查询模式、数据库驱动及相关的中间件。
###
总而言之,分布式数据库系统以其分布透明、高可用、易扩展、高性能的突出特点,已成为支撑大规模、高并发现代软件服务的基石。它为软件开发带来了强大的能力,同时也引入了新的设计模式和权衡考量。成功驾驭分布式数据库,是当今中高级软件工程师和架构师构建健壮、可扩展应用系统的关键技能之一。
如若转载,请注明出处:http://www.yqugames.com/product/71.html
更新时间:2026-06-19 21:41:52